En un artículo anterior describí cómo conectarse a un equipo remoto en una red protegida http://diego-k.blogspot.mx/2014/12/como-conectarme-un-servidor-remoto-con.html .






Esta vez vamos a perfeccionar el método, hacerlo más práctico y a la vez más estable.
El objetivo es el mismo:
"Quieres alcanzar un servidor desde tu PC pero estás detrás del firewall de tu modem y el servidor se encuentra detrás del firewall corporativo. Ambos pueden salir a Internet, pero ninguno publica puertos. "
Tenemos diferentes pasos a seguir:
1) Podemos usar la capa gratuita de Amazon Web Services con un Linux AMI. Hay muchas guías de cómo configurarlo, como la siguiente: How to setup a Linux server on Amazon AWS
En caso de querer hacerlo nosotros mismos necesitaremos una vieja PC, Netbook o Notebook donde instalaremos Linux (puede ser Ubuntu con OpenSSH) y deberemos abrir un puerto para el SSH (recomiendo 443) en el firewall del router. La configuración depende del equipo y el proveedor, pero siempre hay tutoriales.
En caso de querer hacerlo nosotros mismos necesitaremos una vieja PC, Netbook o Notebook donde instalaremos Linux (puede ser Ubuntu con OpenSSH) y deberemos abrir un puerto para el SSH (recomiendo 443) en el firewall del router. La configuración depende del equipo y el proveedor, pero siempre hay tutoriales.
2) En el IBM i o un Linux dentro de la infraestructura donde se encuentra el servidor debemos instalar OpenSSH y AUTOSSH. AutoSSH tiene una sintaxis similar a SSH, pero valida si se ha caído la conexión y la restablece. Con eso evitamos estar validando la conexión. Es muy util en conexiones poco estables.
3) Creamos una cuenta en DynU para que el IBM i encuentre nuestro servidor por nombre en lugar de IP. Si llegara a cambiar y la conexión cayera el AUTOSSH volverá a reconectar de forma correcta.
Instalamos el cliente de DYNU en Linux o podemos agregar un trabajo CRON que ejecute lo siguiente:
* * * * * curl "http://api.dynu.com/nic/update?hostname=myserver.dynu.com&password=MYPASSWORD">/dev/null 2>&1
Este ejemplo refrescará cada minuto la IP pública del servidor myserver.dynu.com . Recuerden, este es el servidor de Amazon o la PC/N*tbook que rehabilitamos para hacer de puente.
4) En el servidor IBM i o Linux creamos un tunnel reverso que publique el puerto de SSH (debe estar encendido el *SSHD) en el puerto 8022 usando AutoSSH.
El script puede ser algo así:
El script puede ser algo así:
autossh -M 10988 -f -N -R 8022:127.0.0.1:22 -p 443 USUARIO@myserver.dynu.com -o "ServerAliveInterval 30" -o "ServerAliveCountMax 3"
NOTA: Es importante que contemos con una llave de SSH para que nos podamos conectar SIN password al servidor Linux en Amazon/Casa/Oficina, como se indica en el artículo que publiqué con anterioridad.
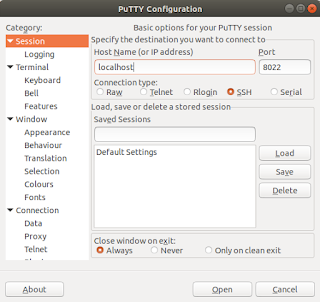
5) En nuestra PC nos conectamos al mismo equipo, redirigiendo el puerto 8022 a nuestra PC:
autossh -M 10986 -f -N -L 8022:127.0.0.1:8022 -p 443 USUARIO@myserver.dynu.com -o "ServerAliveInterval 30" -o "ServerAliveCountMax 3"
(en caso de usar Linux)
o bien con PuTTY:


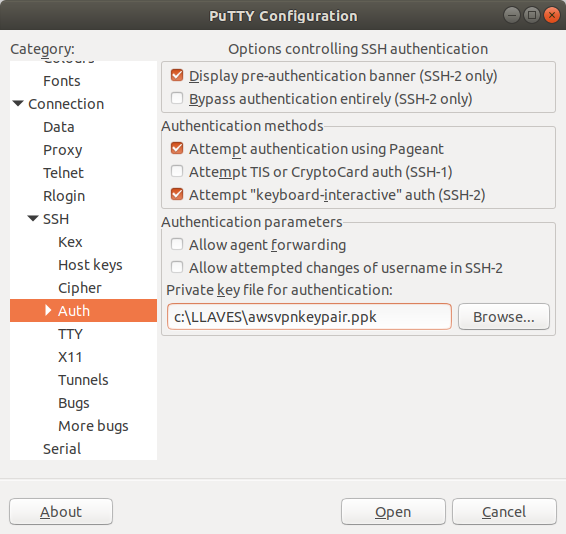

5) Ahora creamos una 2da conexión, pero esta vez a LOCALHOST, en el puerto 8022, para crear el tunel dinámico:
autossh -M 10984 -f -N -D 3128 -p 8022 USUARIO@myserver.dynu.com -o "ServerAliveInterval 30" -o "ServerAliveCountMax 3"
(Linux)
o bien en PuTTY:


Listo, ya tenemos una conexión a través de un equipo que nos hace de puente:

Ahora podemos usar el puerto 3128 en Localhost como un proxy SOCKS 5 en nuestro navegador, en PuTTY, en TN5250j o incluso con Proxychains/TSOCKS o ProxyFier














